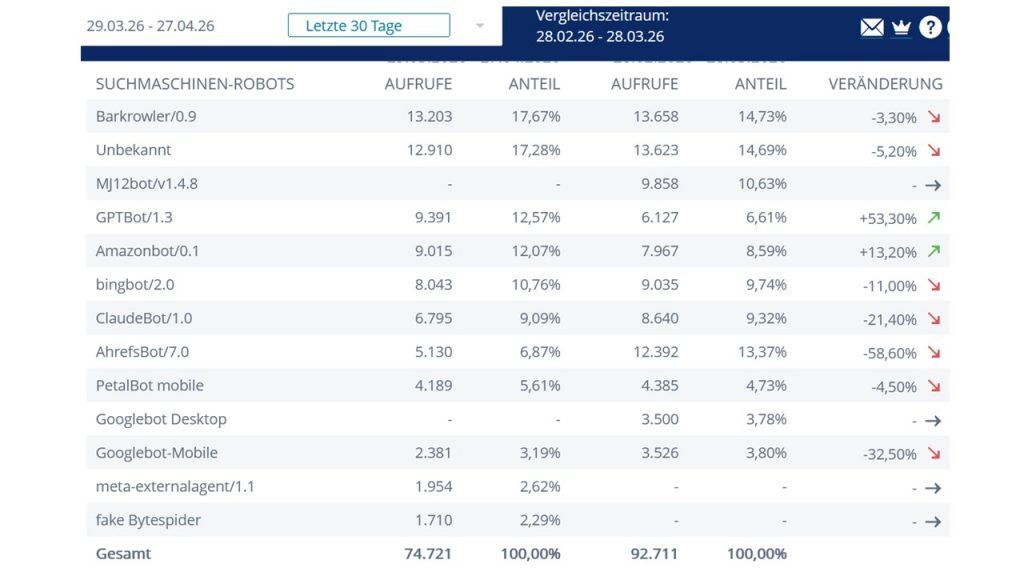
If you ever wondered where the information from AI and AI chatbots comes from, you will not be surprised that this webpage schoemann.org is regularly solicited for such purposes. The number of crawlers, that do so, is quite large. The ability to trace what exactly they are harvesting on your website, is quite a tricky issue. At least a basic awareness of how the internet has been transformed in the last few years becomes evident through the comparison of unique visits, many through search engines like Google search or others, with the amount of contacts by AI-associated crawlers (see slide from own webpage below).
During he last month up to 2026-4-27 there were about 75.000 contacts, compared to 93.000 during the previous month.
At first sight, AI chatbots have largely outnumbered the “personal visits” of my webpage (see evaluate web analytics). On the other hand, I have no information of how many visits are, (at least potentially) re-directed hints from AI chatbots to my content.
In terms of “traffic” for a webpage, the information of how the AI-driven or AI-assisted search operates with other persons’ contributions will be the challenge of the coming years. If AI chatbots had to pay 10 cents per visit, I would have a comfortable pay every month from this content use. The issue of AI paying for access to reliable and high quality content has to be dealt with sooner rather than later. You may prompt a chatbot on this issue.
Meanwhile: My New Book on AI is out Now 2026-4-28:
“AI and Social Science: Potentials versus Limitations” by Dr. Klaus Schoemann, online reading and free download (here) before implementation of Paywall later on.