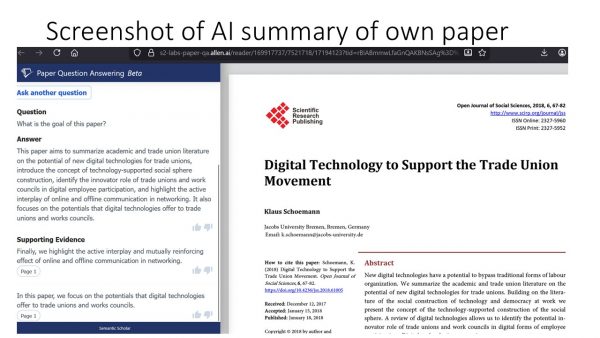
Chatbots are helpful to allow queries to larger data sets like the blog entries here. So here is a try of a Chatbot to query all entries on AI using ChatGPT to create a Chatbot that uses and references it source from www.schoemann.org/tag/ai and the AI reader in pdf-format.
Please send me an email if the hallucinations of this Chatbot 1.0 on AI from a social science perspective are giving strange results. I’ll get back to you. Please use at your own risk as I cannot guarantee for all answers. The usual disclaimer applies here.
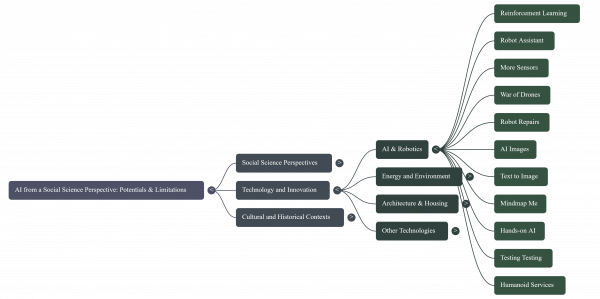
ChatGPT proposed the following set of Questions and Answers on the blog for an entry into the chat: Example Q&A with the chatbot
Q: What are the social science concerns with AI?
A: Bias in results, job shifts, democracy risks, privacy, and new inequalities.
Q: What does the text say about reinforcement learning?
A: It’s seen as the next step for AI: focusing on learning and reasoning, not just predicting text. It also uses fewer resources.
Q: How are robots described in the document?
A: Robots are mostly assistants. They can follow people or carry small items, but more complex tasks need sensors and AI training.
Q: What about biased results?
A: Studies can be misleading if control groups are flawed. AI faces the same challenge — social scientists warn: “handle with care”.
Q: What is Schoemann’s blog view on AI?
A: He links AI to energy use, fairness, and its role in the “all-electric society” — stressing efficiency and responsibility.
More on the chatbot (in testing phase) and the Link to the coding help received from ChatGPT on this mini-test-project :
https://chatgpt.com/share/68c1d160-0cc0-8003-bf04-991b9e7c3b24




























{kind=link}