We know that the scientific and artistic dealings with robots have a long tradition. Whereas art of impressionism took up the challenge to paint the world outside the studio and embellished technological achievements like bridges and trains post hoc, modern extensions of science fiction to the world of robotics has extrapolated from the present. Artists became forerunners of technical evolution and thereby contributed to the acceptance of artificial intelligence to broader audiences. In 2018 The “Grand Palais” in Paris hosted an exhibition on “Artists & Robots” (Pdf booklet). Jérôme Neuters contributed an essay to the catalog of the exhibition on “L’imagination artificielle” which identified a additional role for artists in combination with AI. Some of the early adopters of the new possibilities of robots assisting artists, Nicolas Schoeffer is quoted to state: “l’artiste ne crée plus une oeuvre, il crée la création”. Like an invention of painting techniques or light or perspective in painting, robots allow a new way of representation of emotions or space. (Image Manfred Mohr, 1974 video Cubic Limit, Artists & Robots p.92-93)













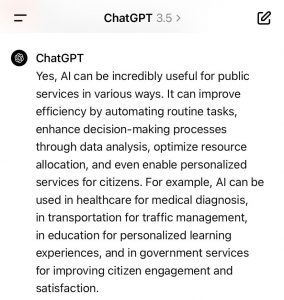 The AI ChatGPT is advocating AI for the PS for mainly 4 reasons: (1) efficiency purposes; (2) personalisation of services; (3) citizen engagement; (4) citizen satisfaction. (See image below). The perspective of employees of the public services is not really part of the answer by ChatGPT. This is a more ambiguous part of the answer and would probably need more space and additional explicit prompts to solicit an explicit answer on the issue. With all the know issues of concern of AI like gender bias or biased data as input, the introduction of AI in public services has to be accompanied by a thorough monitoring process. The legal limits to applications of AI are more severe in public services as the production of official documents is subject to additional security concerns.
The AI ChatGPT is advocating AI for the PS for mainly 4 reasons: (1) efficiency purposes; (2) personalisation of services; (3) citizen engagement; (4) citizen satisfaction. (See image below). The perspective of employees of the public services is not really part of the answer by ChatGPT. This is a more ambiguous part of the answer and would probably need more space and additional explicit prompts to solicit an explicit answer on the issue. With all the know issues of concern of AI like gender bias or biased data as input, the introduction of AI in public services has to be accompanied by a thorough monitoring process. The legal limits to applications of AI are more severe in public services as the production of official documents is subject to additional security concerns.
 (See image). ChatGPT provides a more careful definition as the “crowd” or networked intelligence of Wikipedia. AI only “refers to the simulation” of HI processes by machines”. Examples of such HI processes include the solving of problems and understanding of language. In doing this AI creates systems and performs tasks that usually or until now required HI. There seems to be a technological openness embedded in the definition of AI by AI that is not bound to legal restrictions of its use. The learning systems approach might or might not allow to respect the restrictions set to the systems by HI. Or, do such systems also learn how to circumvent the restrictions set by HI systems to limit AI systems? For the time being we test the boundaries of such systems in multiple fields of application from autonomous driving systems, video surveillance, marketing tools or public services. Potentials as well as risks will be defined in more detail in this process of technological development. Society has to accompany this process with high priority since fundamental human rights are at issue. Potentials for assistance of humans are equally large. The balance will be crucial.
(See image). ChatGPT provides a more careful definition as the “crowd” or networked intelligence of Wikipedia. AI only “refers to the simulation” of HI processes by machines”. Examples of such HI processes include the solving of problems and understanding of language. In doing this AI creates systems and performs tasks that usually or until now required HI. There seems to be a technological openness embedded in the definition of AI by AI that is not bound to legal restrictions of its use. The learning systems approach might or might not allow to respect the restrictions set to the systems by HI. Or, do such systems also learn how to circumvent the restrictions set by HI systems to limit AI systems? For the time being we test the boundaries of such systems in multiple fields of application from autonomous driving systems, video surveillance, marketing tools or public services. Potentials as well as risks will be defined in more detail in this process of technological development. Society has to accompany this process with high priority since fundamental human rights are at issue. Potentials for assistance of humans are equally large. The balance will be crucial.