As a scientist it is in our DNA to cite other scholar’s work with precision. As a university professor your job is to check the quality of citations, kinds of citations and accuracy as a regular part of your job, also as supervisor of junior scientists. In 2026, the use of up-to-date AI (Asai et al. 2026, OpenScholar AI) allows not only to summarise large bodies of scientific literature, but also to cite references and even quotes from the paper(s). Literature reviews used to take months to compile. AI can speed up the process enormously. The citations can be ordered following an own logic or an AI-suggested logic.
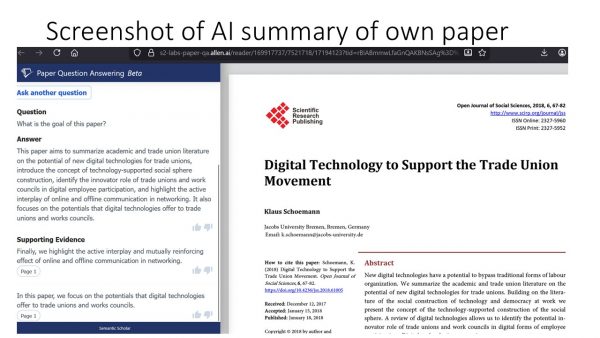
It has become much harder to evaluate the degree of innovation of a candidate for a scientific degree. Tools like retrieval-augmented Language Models enhance the scientific potential of generative AI since they extract more or less short citations directly from the original source just next to the original based on a simple query of author and approximate subject (see screenshot below of own previous publication).
The good news is: (1) referral to previous research and citations should become faster with improved tools for verification. (2) You will find papers written by yourself that you no longer have in your own archive.
The bad news is: (1)self-citations of researchers might become more feasible, although this problem is conditional on a researcher’s seniority. (2) so far, Language models prioritise specific languages (although not necessarily) and differentiate names with “foreign” characters e.g. “ö,ä,é” and do not double check “close neighbours” of them like “o, oe, a, ae, ue, e, ê, è” leading to a “character based normalisation bias“.
It is, of course, rather easy to point out deficiencies of the search, sorting and inclusion algorithm if you know already about the complete picture of a data set.